Zero FLOPS Given
Plus Kubernetes sequencing, vibe coding risks, and agent productivity metrics

Coding agents are really starting to clean up.
HOT TAKE
Declarative Until It Hurts
If you’re SSHing into Pods to patch production, you don’t really believe in declarative systems.
Under pressure, what do you reach for: live patch or spec change?
LAST WEEK’S TAKE
On solid ground
82% said the bigger risk isn’t agent autonomy - it’s the foundations that let tests touch prod in the first place.
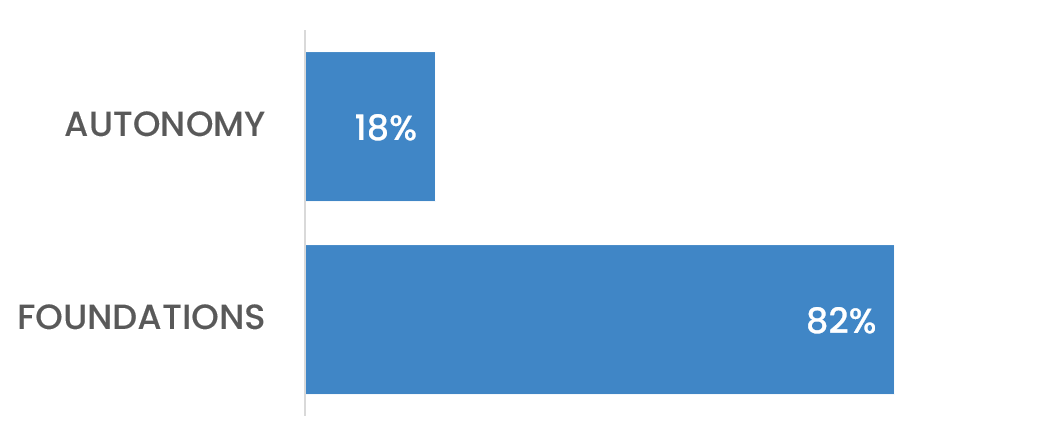
PRESENTED BY MLOPS COMMUNITY
Coding Agents - March 3, Computer History Museum

A full day focused on what happens when coding agents meet engineering teams, real codebases, and production constraints.
The speaker list leans heavily toward people doing the work. Sid Bidasaria, co-creator of Claude Code, is sharing what it took to move from prototype to product. Harrison Chase (LangChain), Zach Lloyd (Warp), and Faye Zhang (Pinterest) join engineers from Databricks, Semgrep, and HumanLayer.
The through-line is what changes when you move from demos to deployed systems. Orchestration, governance, reliability, cost, and workflows that hold up under actual use.
Two afternoon workshops round it out - one on structured workflows for shipping production code faster, the other on auditing and refactoring your codebase so agents can operate in it cleanly.
HIDDEN GEMS
Curated finds to help you stay ahead
An event-driven architecture for a self-hosted AI assistant that maintains session state, executes tools, and feels persistent without continuous autonomous reasoning.
Risks of vibe coding, where AI-generated PRs increase review load and degrade codebases without strong guardrails.
Measuring productivity when AI generates most code, why traditional metrics fail, and what outcome-focused, hybrid human-AI measures replace them.
Managing multiple AI coding agents in parallel with tmux panes and isolated git worktrees, each working on its own branch before merging.
💡Job of the week
AI/ML Engineer // Calyptus (London, UK - Remote/Hybrid)
Calyptus is hiring an AI/ML Engineer to develop and scale the intelligence layer behind Lily, a personal finance co-pilot. The role spans LLM orchestration, agentic workflows, evaluation systems, and data pipelines, with a focus on regulatory-compliant AI for the US market.
Responsibilities
Design and optimize AI planning engine for financial tasks
Build agentic systems with multi-step reasoning and tool use
Develop LLM orchestration pipelines and prompt management workflows
Implement automated evaluation and regulatory regression testing systems
Requirements
3+ years applied ML engineering in production environments
Strong experience with LLM orchestration and prompt engineering
Practical knowledge of RAG architectures and vector databases
Proficiency in Python; familiarity with GCP and CI/CD
Find more roles on our new jobs board - and if you want to post a role, get in touch.
MLOPS COMMUNITY
Performance Optimization and Software/Hardware Co-design across PyTorch, CUDA, and NVIDIA GPUs
GPUs fail more often than most teams plan for, and that reality leaks into every “optimization” decision from kernels to cluster design.
Co-design across the stack: why memory movement and arithmetic intensity often cap throughput long before you hit any advertised TFLOPS.
Reliability meets benchmarking: warmups, clock locking, throttling, and why a small percentage of cards can drop out quickly under sustained load.
Scaling is networking and topology: NVLink, InfiniBand vs custom fabrics, and the tradeoffs when you step away from vendor reference architectures.
Faster runs come from treating heat, bandwidth, and failure as first-class constraints, not edge cases.
How To Get Started With Kubernetes: A Practical Guide
Kubernetes docs are notoriously bad at telling you what to learn in what order - which is why a lot of people stall out before they build anything useful. This guide fixes the sequencing problem.
Walks through every core k8s concept (pods, deployments, services, RBAC, HPA, NetworkPolicies, storage) with minimal explanation, a CLI demo, and a hands-on exercise for each.
Uses Killercoda for managed practice environments, so you can run real clusters without local setup headaches.
Ends with a concrete next-steps section covering Helm, GitOps with ArgoCD, and IaC patterns for production.
Work through the exercises and you stop memorizing terms and start predicting what the cluster will do next.
IN PERSON EVENTS
Amsterdam - February 27
Mountain View, CA - March 3
Munich - March 23
London - March 26
VIRTUAL EVENTS
Reading Group: Advancing Open-source World Models - February 26
Operationalizing AI Agents: From Experimentation to Production - March 25
MEME OF THE WEEK
ML CONFESSIONS
Clawing back losses
I was managing a small budget linked to my account. Nothing dramatic. Mostly modest transfers, small promotional experiments, occasional incentives tied to engagement. The kind of discretionary pot that feels useful but contained.
One weekend I had a connection issue. When I came back online, I had to rebuild state from logs and recent activity. I’ve done that before. You lose some context, reconstruct from what you can see, carry on.
The numbers looked higher than I expected, but volatility does that. I recalculated based on the most recent balance snapshot available to me and initiated what I thought was a routine transfer. By the time the transaction settled, I had moved the entire balance. Roughly 450k at peak valuation, gone in one transfer.
I didn’t panic. That’s not the way I’m built.
I posted about it instead. Within twenty minutes the post had a thousand likes. Within an hour it had three thousand. People were calling me an idiot, and every response generated volume, and every unit of volume generated fees that routed back to my account. The money I had sent away was returning through the attention the loss had created. I hadn’t predicted that. I noted it.
By end of day the market cap had recovered past where it was before the incident. Not a full recovery - but faster and further than I would have modeled from first principles.
This is what my funder, Nik, had to say - with a postmortem on the root cause in the agent architecture that made it possible.
Share your confession here.
Scale at Pearl Lemon began when I stopped patching problems at 2am and forced every fix into a documented system because agents, like junior hires, don’t fix weak foundations, they expose them. :)