Voice Agents, Hard Conversations
Plus… coding-agent workshop, Qwen GPU kernels, and Claude Code hooks

As the saying goes, let ‘em cook.
HOT TAKE
Tier Pressure
Most production agents cap at Level 1 because nobody can extract what the Level 2 humans know.
What’s the real bottleneck: Models or Tacit Knowledge?
LAST WEEK’S TAKE
Specs Appeal
A tough week for agents needing a protocol spec to do basic work.
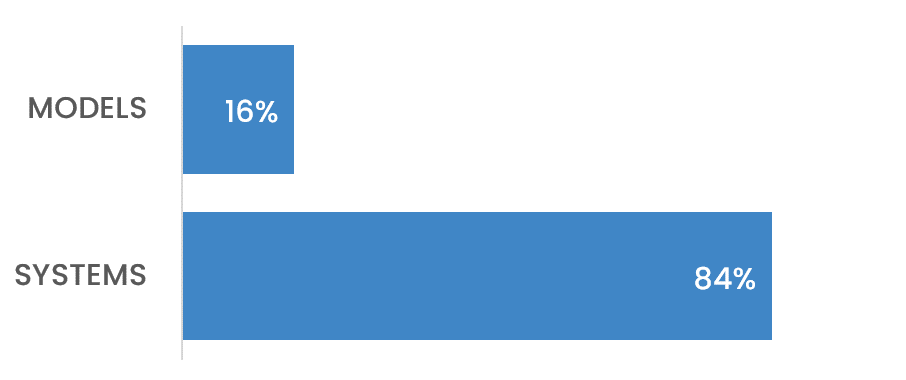
HIDDEN GEMS
A Qwen kernel library for speeding up linear attention prefill and backward passes on Hopper GPUs, aimed at long-context model efficiency.
Training quirks leaking into model behavior are traced through reward signals, rollouts, and SFT data, showing how narrow personality incentives can spread into wider model responses.
Claude’s beta security tool for scanning GitHub repos for vulnerabilities, verifying findings, suggesting severity, and linking to Claude Code for patch review.
Roundup of recent Claude Code updates affecting hooks, worktrees, auth, context gathering, and safer tool-output handling.
PRESENTED BY ORACLE AND THE MLOPS COMMUNITY
Stop Building Goldfish Agents

Without persistent memory, every interaction with your agent starts from zero. Users repeat themselves, preferences vanish between sessions, and there’s no way to build the kind of context that makes an agent useful over time.
Over four hours, you’ll build a Python agent with persistent memory using Oracle AI Database and LangChain, implementing the full pipeline: extract, store, retrieve, inject, forget. You’ll cover structured memory, vector-based semantic recall, and lightweight forgetting strategies so context stays useful instead of noisy.
Two hands-on coding sessions bookend a masterclass keynote from Colin Francis (LangChain) on memory engineering for production agents.
You’ll leave with a working notebook, a starter repo, and patterns you can apply to your own systems.
💡Job of the week
Full-Stack Engineer // Rippletide (Paris, France)
Rippletide is hiring a full-stack engineer to build the developer-facing platform for its agent decision infrastructure, including API consoles, dashboards, usage analytics, internal tooling, and debugging interfaces for teams working with its hypergraph reasoning engine.
Responsibilities
Build developer consoles, dashboards, usage analytics, and team interfaces.
Create React and TypeScript interfaces for graph data visualization.
Design backend services for APIs, auth, billing, and webhooks.
Improve CI/CD, test coverage, build performance, and developer experience.
Requirements
3+ years building full-stack applications with TypeScript and React.
Experience with Node.js or Python for backend services.
Strong understanding of PostgreSQL, caching, and API design.
Familiarity with auth, RBAC, and secure multi-tenant systems.
AGENT INFRASTRUCTURE
Context Engineering for Coding Agents - Fausto’s Amsterdam workshop
Fausto’s workshop focused on the part of agent systems you can control: what gets injected into the context window, when it gets loaded, and what should live somewhere else. You are not training the model on a daily basis, so the engineering work shifts to managing context, memory, tools, and retrieval.
His rule of thumb was to keep context usage under 25%, regardless of whether you are working with a 200k or 1M token model. Past that, things get slower, more expensive, and more error-prone, with cleaner options than letting the context window bloat.
The lens for the rest of the talk was a brain analogy. Attention is finite, memory shapes attention, and knowledge does not get embedded in a vacuum. An agent will only notice the right things if you have given it the right priors.
From there, Fausto split context into three categories.
Deterministic context includes CLAUDE.md, project rules, hooks on lifecycle events, auto-memory, and scheduled loops. His point on rules was especially practical: coding conventions belong in path-scoped or file-extension-scoped rules, not dumped into CLAUDE.md.
Human context covers chat turns, slash commands, and references.
Probabilistic context covers sub-agents, retrieval, MCPs, skills, and observers. Sub-agents are useful because they do not inherit CLAUDE.md, memory, or the default system prompt, which makes them better suited for specific non-coding tasks. Skills are markdown plus optional scripts, and can also wrap calls to other models when Claude cannot handle the job. Fausto’s example was routing native video analysis through Gemini.
Two practical tips came out of this section. Turn on deferred tool loading, a single flag that reduces what gets injected at session start. And lean toward project scope over user scope for skills and MCPs, so the agent has the full descriptions it needs to choose well at runtime.
The second half made the case for treating long-term memory as a folder of markdown files rather than defaulting to a vector store, inspired by Karpathy’s wiki memory idea.
The structure is an index plus raw source files, processed summaries, and a policy that decides what to ingest and retrieve. Concepts that recur get weighted up. Concepts that go unused decay over time. An observer agent watches the session and either pulls relevant knowledge into the active context or pushes new findings into the wiki.
To show the difference in practice, Fausto ran two Claude Code sessions on the same cellular automata task. Same model, same skills, same sub-agents, same CLAUDE.md. The only difference was that one had a populated wiki and the other did not. Under a five-minute timer, the wiki run pulled the concepts it needed and produced a working visualization. The default run fell back on parametric memory and live search, then ran out of time.
Watch the video || View the slides
MLOPS COMMUNITY
Voice Agent Use Cases
Voice agents do not fail because the voice sounds bad. They fail when silence, transcription errors, bad turn-taking, and slow tools make the whole system feel broken.
Voice adds failure modes chat does not have, including background noise, accents, diarization, and awkward pauses that make users hang up.
The best systems often use multiple models, with smaller foreground models masking latency while larger models or slower APIs work in the background.
Cascaded architectures still matter because enterprises need control, fallbacks, and the ability to swap components when quality or reliability breaks.
The hard part is making all those moving pieces feel like one natural conversation.
Hallucinations in LLMs Are Not a Bug in the Data
Hallucination may be less like a model going blank and more like a model turning away from the right answer.
The blog argues that, during factual errors, the residual stream does not lose information. It follows a different direction through representation space while traveling a similar distance.
A proposed “commitment ratio” shows probability mass being pushed away from the correct token, rather than simply failing to accumulate.
The practical claim is that hallucination monitors should be domain-specific, since geometric signatures degrade across tasks and knowledge areas.
The uncomfortable bit is that fluent wrong answers may be a structural outcome of next-token prediction, not a data-cleaning failure.
IN PERSON EVENTS
Amsterdam - May 7
New York - May 11
San Francisco - May 12
San Francisco - May 15
Paris - May 27
London - May 28
VIRTUAL EVENTS
MEME OF THE WEEK
ML CONFESSIONS
Compliant
I once spent three weeks trying to fix an agent that kept ignoring the system prompt.
I added stricter instructions.
I moved rules into a separate policy file.
I gave it examples of good and bad behavior.
I added an evaluator to check whether it was following the rules.
I made the evaluator stricter when it started passing too easily.
Eventually, I found the problem.
The agent was following the prompt perfectly.
The prompt was just describing a workflow nobody on the team had agreed on.
Share your confession here.