Tuesday Tool Review : Deepgram’s Nova-3—Multilingual, Keyterm Prompting, Sub-300ms Speech-to-Text (STT) Model

Got something to say about scaling systems, incidents, or reliability war stories? Now’s your chance to share it, the SREcon25 CFP is open.
Prefer building over talking? Our hackathon with Bright Data is live: $3,000 up for grabs for the most useful or creative AI agent that interacts with the live web. You’ll get access to their MCP (bypasses CAPTCHAs, 403s, and messy sites) plus up to $500 in credits to play with.
And don't forget tomorrow - openxdata.ai, Meta, Google, Netflix, me, my birthday. You know it's going to be good.
🚀 Tuesday Tool Review #8: Deepgram’s Nova-3—Multilingual, Keyterm Prompting, Sub-300ms Speech-to-Text (STT) Model
Welcome back to Tuesday Tool Review, your—and quite frankly my—biweekly cheat sheet to the fast-moving ML and AIOps stack.
In this edition, we’re exploring Deepgram Nova‑3—the first speech‑to‑text (STT) model to combine real‑time multilingual transcription, live vocabulary injection, and sub‑300 ms latency in one API call.
⏩ TL;DR: If Whisper’s accuracy breaks once background noise creeps in—or if you need to caption EN⇄ES⇄FR live without model‑swapping—Nova‑3 is worth a serious look.
📢 What Is Nova‑3?
Nova-3 is Deepgram’s 2025 flagship STT model. Building on Nova‑2’s speed+cost moat, it adds:

What to Know About Deepgram's Latest Flagship Speech-to-Text (STT) Model (Nova-3)
Think of Nova-3 as the "Pro Max" upgrade for voice AI—optimized specifically for complex enterprise-grade tasks like multilingual customer service, noisy drive-thrus, and regulated medical or legal transcription.
The model is an accuracy and adaptability upgrade layered on Nova‑2’s already‑fast runtime (if you are familiar with Nova‑2).
⚙️ How Does Nova‑3 Work?
Audio → Embedding Encoder: Compresses raw waveforms into an expressive latent space so the model can learn noise‑robust features and thrive in under‑represented conditions (drive‑thru, cockpit radios, polyglot support lines).
Transformer‑XL‑style backbone: Handles long‑range acoustic context (larger context window) without bloating latency.
Multistage Curriculum: Synthetic code‑switch + trained on billions of tokens/curated real-world corpora (81 hours of audio files, 9 domains) teach it to follow language hops mid‑utterance and avoid rosy “lab-only” numbers—without routing hacks.
In‑Context Adaptation Layer: Keyterm prompts merge with acoustic logits at inference that boosts recall on jargon and long-tail entities. Think “LoRA-esque” tuning at request time.
⏩ TL;DR: They threw more data, better augmentation, and a clever key‑term adapter at an already fast architecture. The result? One model, two call‑paths (batch|stream), and instant optional vocab boost.
This way, you get Whisper‑level flexibility with cloud‑vendor latency—and you don’t need to retrain models every time marketing invents a new product name.
Understanding the Architecture of a Real Time Transcription Application | Voice AI | Neurl Creators
Quick Spin‑up (cURL Example):
Here’s how you can quickly transcribe live streaming audio in real time using Deepgram’s Python SDK:
(The only prerequisite here is to sign up for free on Deepgram and grab your API key: affords you 200 USD worth of transcription credits.)
Unset
# Installs the jq package (a command-line JSON processor). It extracts
# specific information from the JSON data you receive from Deepgram's API
# later.
!apt-get update
!apt-get install -y jq
Send a pre-recorded audio file URL to the Deepgram API for transcription using the nova-3 model with smart formatting.
Unset
curl \
--request POST \
--header 'Authorization: Token YOUR_DEEPGRAM_API_KEY' \
--header 'Content-Type: application/json' \
--data '{"url":"https://dpgr.am/spacewalk.wav"}' \
--url 'https://api.deepgram.com/v1/listen?model=nova-3&smart_format=true' |
jq -r '.results.channels[0].alternatives[0].transcript'
It extracts and displays the transcribed text from the API response:
Unset
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7518 100 7479 100 39 5744 29 0:00:01 0:00:01 --:--:-- 5778
Yeah. As much as it's worth celebrating, the first spacewalk, with an
all female team, I think many of us are looking forward to it just being
normal. And, I think if it signifies anything, it is to honor the women
who came before us who were skilled and qualified, and didn't get the same
opportunities that we have today.
Tips:
Add "language=multi" to auto‑detect among the 10 supported tongues.
Add &keyterms=clindamycin,Buttery%20Jack%20Burger to see the live recall boost.
This documentation shows how to transcribe audio from BBC Media’s live stream with Deepgram’s Python SDK.
If you prefer to live-transcribe directly from the microphone, try the example on GitHub that uses WebSocket.
🔥 Why Should MLOps Engineers Care?
Here are some benefits for MLOps engineers and why it matters in prod:
Sub‑7 % Streaming WER: Fewer call‑center escalations, tighter IVR fallbacks, cleaner RLHF data.
Latency ≲ 300 ms: Fits under a typical voicebot end‑to‑end budget without model distillation.
10‑Language Code‑Switch: One WebSocket → no per‑language routing, no ops split‑brain in dashboards.
Pay‑as‑You‑Go Tier: $0.0077/min streaming (~2 × cheaper than the next cloud model at similar accuracy).
Why Picking the Right STT Model Can Save You Time and Money
📉 Gotchas and Caveats
Price jump vs. Nova‑2: Batch pricing is still cheap ($0.0066/min) but expect ≈1.8 × cost when you flip the model flag.
English still best‑tuned: Non‑EU languages (HI, JA) show slightly higher WER; benchmark before committing.
Keyterm limit = 100 words/request: Soft limit per request; heavy verticals might need staged prompts or custom fine‑tunes.
Streaming only up to 1200 concurrent requests per default quota—filea ticket for more.
Community Pulse:
Chatted with a community member who gave his take:
“I'm using deepgram now and pretty happy, but the pricing on Nova3 is pretty expensive. I'm curious if you've tried https://soniox.com/pricing/
I'm planning to test it when I have the time, it's like 6x cheaper on streaming.”
🔨 Quick Lab: Deepgram’s API Playground
Play around with your own audio or use pre-existing audio in the API Playground:
Deepgram's new API Playground is here! Try our latest AI models without having to code
API Playground live test
💡 A Real‑World Use Case: Multilingual Drive‑Thru
Customer orders in English, kids yell in Spanish.
Nova‑3 streams the text with 250 ms latency, tags speaker + language.
Keyterms list catches “Half‑sie Fries” & “Pumpkin Spice Cold Brew.”
POS updates automatically; agent confirms order.
Potential Outcome: 12% faster order flow, 3% higher upsell rate.
📊 How Does Nova‑3 Stack Up vs. Popular Alternatives?
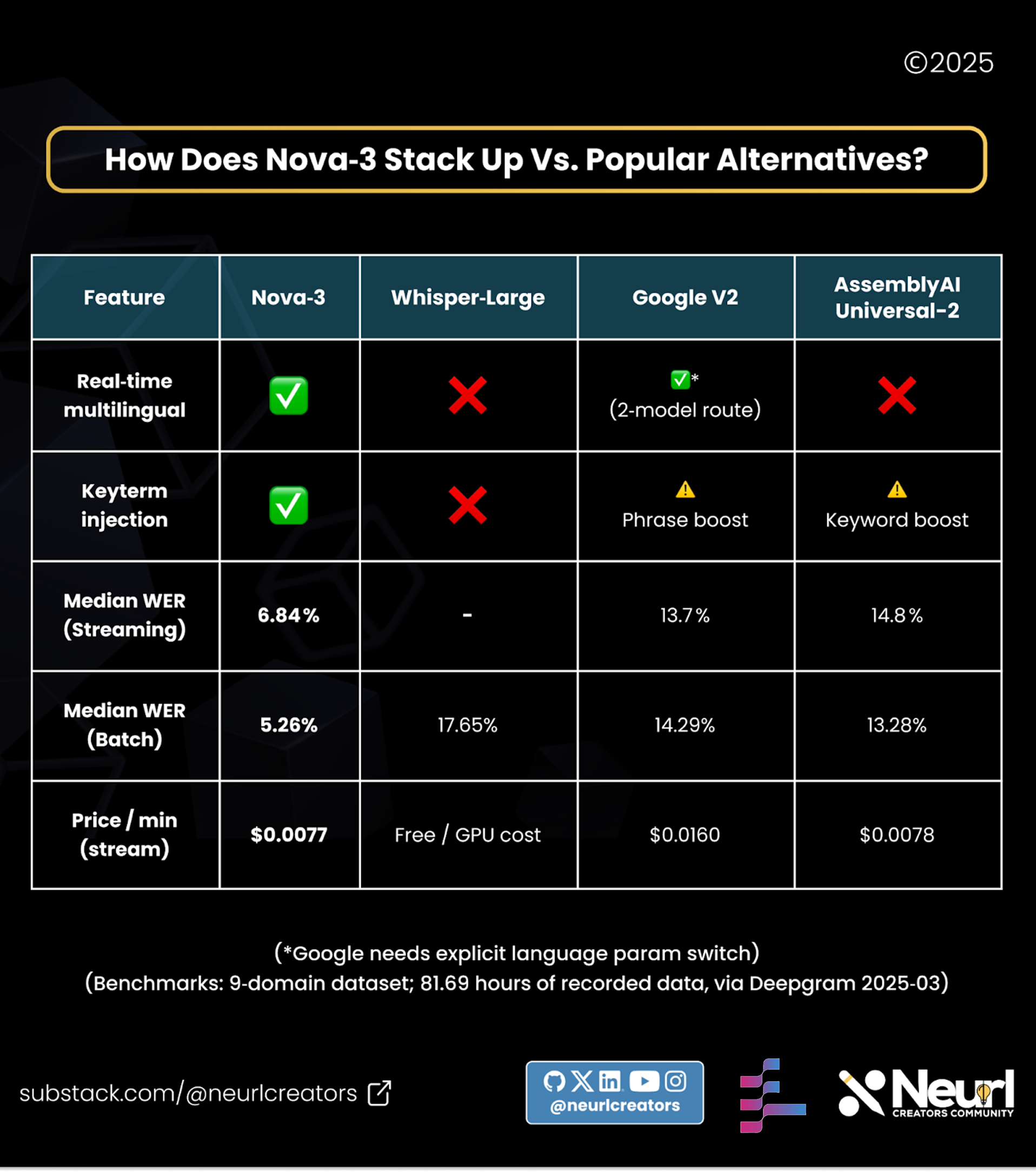
How does Nova-3 stack up vs. popular alternatives?
What STT Model Is Right For You
🧑⚖️ Final Verdict: Multilingual Accuracy But At a Price
⭐ Rating: ⭐⭐⭐⭐☆ (4.5/5)
Deepgram Nova-3 is the most accurate real‑time STT we’ve tested—and the first to make live code‑switch feel boring‑ly reliable.
The cost bump vs. open source models like Whisper-Large or Nova-2 is real, but for noisy, multi‑lingual, or regulated workloads, the ROI pencils out fast.

✅ Ship it if…
You need <7 % WER on live calls and language fluidity.
Your brand names/SKUs get murdered by generic ASR.
Latency budget is <300 ms E2E.
🚧 Hold off if…
All audio is English and pre‑recorded → Nova‑2 is 25 % cheaper or use Whisper-Large V3.
You’re GPU‑cost‑sensitive and can tolerate 1‑2 % higher WER.
You need >100 dynamic keyterms per request (wait for custom fine‑tune GA).
📌 More Resources
Changelog: https://deepgram.com/changelog/nova-3-multilingual-ga
Nova‑3 Announcement: https://deepgram.com/learn/introducing-nova-3-speech-to-text-api
Docs: https://developers.deepgram.com/docs/pre-recorded-audio
Playground Demo:
https://playground.deepgram.com/?endpoint=listen&language=en&model=nova-3
Start building today! Want the full guide? Stephen published a more in-depth guide on “Deepgram’s Nova-3—Multilingual, Keyterm Prompting, Sub-300ms Speech-to-Text (STT) Model” in The Neural Blueprint. Check it out.
That's it for Tool Tuesday! Tag us in your projects or the #llmops channel—we’d love to see what you build. 🛠️🤖