Taming the Context Demon for Devs
Plus… graph myths busted, self-prompting experiments, and smarter evaluation.


I think Jeff Goldbloom should be on the board of OpenAI.
HOT TAKE
Edges or Embeddings?
For relationship-heavy queries, index-free adjacency beats cosine guesses every time.
Which wins for you when relationships drive answers?
LAST WEEK’S TAKE
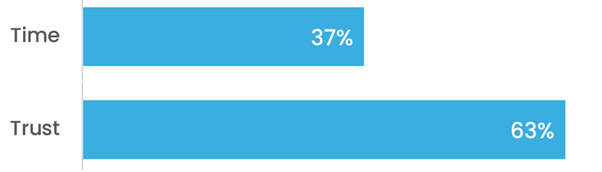
We trust you
The results are in, and most picked trust over speed.
PRESENTED BY GUARDRAILS
Beyond Benchmarks: Why Simulation is the Missing Piece in AI Testing

If you’ve built AI agents, you know how challenging it is to test them. How do you even begin formulating a test plan for a technology whose input space is infinite?
Join us for a fireside chat between Demetrios, Founder of MLOps Community, and Shreya Rajpal, Founder and CEO of Guardrails AI and Snowglobe, on techniques on how to systematically test AI applications.
HIDDEN GEMS
Curated finds to help you stay ahead
Experiments in self-prompting explore how LLMs generating their own instructions shifts ideas of reliability, alignment, and practical use.
FHIR-native pipelines in Python are implemented in this repo for connecting AI models to healthcare data sources, with more context and design principles detailed in this blog on modernizing healthcare AI.
Preference optimization and evaluation are set in context alongside supervised fine-tuning, showing how different post-training steps shape LLM behavior and the trade-offs between them.
Hybrid preference optimization for musical intent fuses reward models and direct preference optimization to help an LLM-driven system generate playlists that evolve with user feedback.
Job of the week
AI Product Engineer, New Grad // Arize (Remote)
Arize is hiring for a graduate-level role focused on building tools for AI and LLM-powered applications. The position involves working with senior engineers on core product development, tackling complex technical problems, and contributing to AI observability and evaluation systems.
Responsibilities
Build APIs and infrastructure for AI observability and evaluation
Develop systems handling millions of real-time annotations per second
Contribute to tools for prompt engineering and agent development
Implement scalable model evaluation and data analysis solutions
Requirements
Bachelor’s degree in Computer Science or related field
Proficiency in Go, Python, Java, or TypeScript
Strong problem-solving ability and willingness to learn quickly
Commitment to high code quality and critical system design thinking
Find more roles on our new jobs board - and if you want to post a role, get in touch.
MLOPS COMMUNITY
Beyond Prompting: The Emerging Discipline of Context Engineering
A 60-page survey made one thing clear: context is the bottleneck and the opportunity. The quadratic cost of attention is the ever-present demon, so the field is reorganizing around smarter context, not longer prompts.
Foundations - Context generation, processing, and management as first-class components, assembled dynamically under strict compute limits.
RAG + memory - Modular, agentic, and graph-enhanced RAG like LightRAG, plus stateful memory systems such as mem0 for factual, episodic, and semantic recall.
Tools + agents - Function calling, MCP-style tooling, and coordinated multi-agent workflows for real-world action.
Payoff: structure the context pipeline and you tame the demon - performance follows.
The Misunderstood World of Knowledge Graphs
Most of your data is already a graph - you just haven’t called it one. Yet misconceptions about graph databases keep teams locked into flat tables even when context and relationships matter most.
Flexibility vs. rigidity - Graph schemas aren’t brittle; they evolve incrementally and can be as loose or as constrained as you need.
Speed myths - Modern in-memory graph systems hit millisecond lookups at billion-scale, thanks to index-free adjacency and parallel traversal.
AI-driven construction - LLMs now help build graphs directly from structured and unstructured data, accelerating entity extraction and schema design.
The takeaway: graphs aren’t exotic - they’re how machines (and humans) actually think.
IN PERSON EVENTS
South Bay - October 8
Charlotte, NC - October 15
Amsterdam - 16 October
Barcelona - October 22
MEME OF THE WEEK

ML CONFESSIONS
Over-Regularized and Underwhelming
I once built a recommender system that looked amazing in offline metrics, but in production it just kept pushing the same three “safe” items to everyone. Product thought it was a bug, but really I’d just over-regularized the model. We ended up reverting to a simple popularity baseline for weeks while I pretended it was “intentional A/B testing”.
Share your confession here.