QA the agent, not the code
Plus... tool design for messy search queries, hidden infrastructure debt in production agents, and persistent memory that beats RAG.

Before you vibe-code your billion-dollar idea, make sure you’ve got a vibe strategy.
HOT TAKE
Fluent Nonsense
Better models don’t fix bad interfaces. They just fail more convincingly. What do you optimize first: model or interface?
LAST WEEK’S TAKE
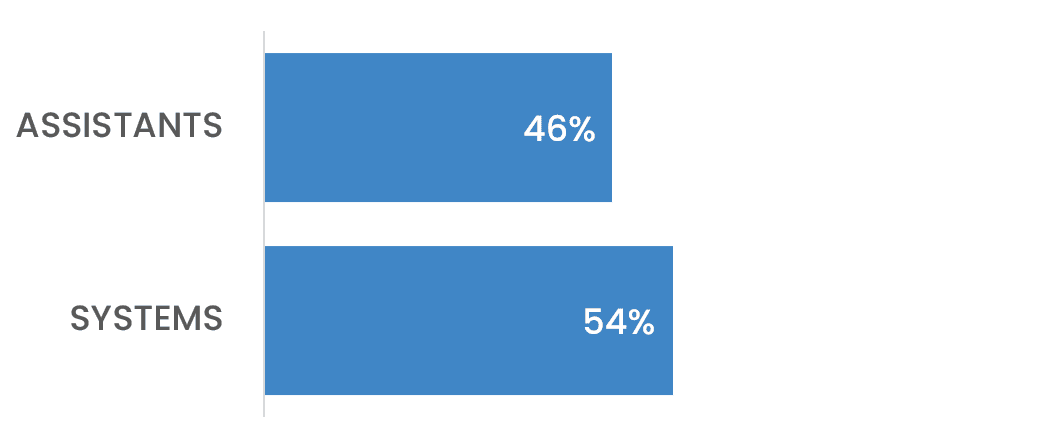
Legacy, Apparently
The “single-agent is legacy” call runs slightly ahead of reality - assistants are still holding nearly half the vote.
PRESENTED BY MLOPS COMMUNITY
When your context window fills up before your agent’s done anything useful

You’ve watched an agent chew through its context budget before it’s shipped a single useful output.
That’s one of the production constraints covered at the AI Agents Summit on April 14. Rodney Shen from TextQL is arguing for sandboxes instead - skills and credentials co-located with execution, no bloat, no subprocess dependencies you don’t own.
Ten talks on what it takes to run agents in real systems - from durable runtimes and orchestration to what breaks after deployment.
Speakers include engineers from Google, Meta, Microsoft, Intuit, Orkes, Union.ai, Zipline AI, Braintrust, and Databricks.
Museum of Flight, Seattle. April 14.
HIDDEN GEMS
Curated finds to help you stay ahead
Framing agents as seven layers of hidden infrastructure debt, covering orchestration, state, reliability, and evals that emerge once systems move past demos into production.
Multilingual embedding model for retrieval and RAG, with long-context support and instruction-tuned queries improving search and clustering across 90+ languages.
Automating agent harness optimization with eval loops and meta-agents, improving prompts, tools, and workflows without manual tuning.
Persistent memory system for agents that stores raw interactions and retrieves them efficiently, improving long-term recall, consistency, and cost compared to standard RAG approaches.
💡Job of the week
Staff Software Engineer, AI Research // Dataminr (US Remote)
Dataminr builds systems that detect and interpret real-time events from large-scale multimodal data. This role focuses on designing, training, and deploying LLM-driven systems within a high-throughput platform handling billions of daily inputs.
Responsibilities:
Design and deploy LLM-based systems across multimodal data pipelines
Build APIs, libraries, and container strategies supporting LLM lifecycle
Optimize training and inference performance on specialized compute hardware
Translate research into production systems through experimentation and implementation
Requirements:
Experience training and deploying deep learning models beyond API usage
Strong Python skills with production-level software engineering experience
Familiarity with transformers, LLMs, and multimodal AI systems
Experience with Kubernetes, AWS, Databricks, and agent tooling frameworks
MLOPS COMMUNITY
Getting Humans Out of the Way: How to Work with Teams of Agents
The slow part is no longer writing code. It is proving the agent did the right thing before bad work slips through.
Replace manual QA with screenshot-based walkthroughs that show each feature working, then have a second agent verify the evidence before anything gets approved.
Treat validation as the real control layer by using lint rules, unit tests, and file-level documentation to force cleaner code and make repos easier for agents to navigate.
Ask agents what was hard and build tools around the answer, because that is often where the next bottleneck, cost spike, or hidden maintenance problem starts.
The result is a shift from writing every line yourself to building the checks, tools, and structure that let agents work without making a mess.
Engineering An AI Agent To Navigate Large-scale Event Data - Part 2
Search is easy until the question has two parts, three filters, and nowhere obvious to look. This piece shows how an event-search agent stays useful once queries stop being tidy.
It turns a pile of database query patterns into seven tools the agent can reliably choose between, instead of leaving the model to improvise every step.
It treats tool design as the hard part: self-contained workflows, typed parameters, structured outputs, and errors the agent can recover from.
It shows why prompts still matter, with few-shot examples teaching better tool choice, parameter selection, and multi-step chaining.
The result is an agent that can break down messy search questions and answer them with less guesswork.
IN PERSON EVENTS
Seattle - April 14
Amsterdam - April 21
San Francisco - May 15
VIRTUAL EVENTS
Coding Agents Lunch and Learn - Skill Building Workshop (From Idea to Evaluation) - April 10
MEME OF THE WEEK
ML CONFESSIONS
Legacy Feature
Inherited a feature store from a guy who left. Nobody understood his transforms, but the model metrics were solid, so we left it alone. Six months later I finally traced through the pipeline and found one of the “engineered features” was just the target variable, lagged by one row. Not a clever temporal feature. A pandas off-by-one error. Removing it dropped accuracy by eleven points. I put it back, added a comment that said “DO NOT TOUCH - legacy feature,” and closed the ticket as “investigated, no action required.”
Share your confession here.