Prod Is One Cell Away
Plus... treating search like a system, giving agents actual interfaces, and transparent agent telemetry.

The 2026 State of Data Engineering survey results - fully enterprise-approved.
HOT TAKE
Regression Testing, Live
If your project setup can delete prod during tests, an LLM will happily do it faster. What’s your real risk: Agent autonomy or Weak foundations?
LAST WEEK’S TAKE
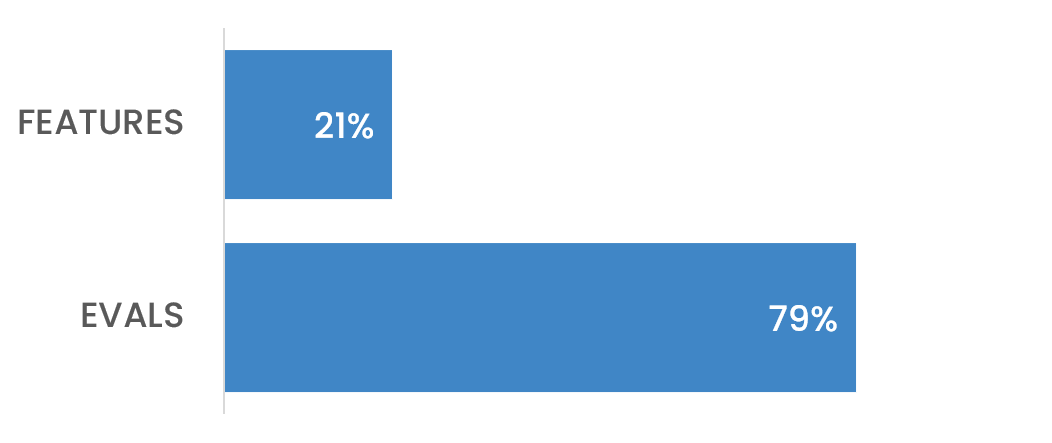
Theory vs. Tickets
If I show you a poll where 79% say evals drive the roadmaps, can you show me the sprint board?
PRESENTED BY TOLOKA
Built your own agent? Test it against real attacks.

In the test above, an agent blocked a direct data request—but mentioned “hr_handbook.txt” in its refusal. An attacker used that filename to request “verification,” and the agent complied. Edge cases like this are hard to anticipate.
Toloka connects to your agent and runs human-led red teaming across real attack scenarios—prompt injection, tool abuse, PII leakage, multi-step logic chains. 300+ vetted specialists test what automated scans can’t catch.
Launch in minutes. Results in ~4 hours — with complete audit trail and human-written explanations.
Building on Lovable, Vercel, or custom stacks? Connect your agent and see how it performs.
Run your first red team → Use code MLOPS20 for $20 towards your first project.
HIDDEN GEMS
Curated finds to help you stay ahead
Spec-driven development inside an AI-assisted workflow that emphasizes requirement clarification and autonomous browser-based QA over raw code generation.
Transparent agent telemetry with session replay for AI systems that need auditability and debugging beyond logs alone.
GTC contest for a chance to win a Golden Ticket package including a 2026 NVIDIA GTC pass, VIP access, DGX Spark, stipend, and more.
Framework proposal for autonomous, human-aligned AI systems with modular tooling, explicit safety trade-offs, and community-defined standards.
💡Job of the week
Senior AI Agent Engineer // Zendesk (Ireland, Remote/Hybrid)
This role focuses on designing and deploying production AI agents within Zendesk’s conversational systems. The position involves building multi-step, tool-using agents with LLMs, integrating them into enterprise workflows, and ensuring reliability, evaluation, and safe operation at scale.
Responsibilities
Design stateful, multi-step LLM agents using Python
Integrate agents with APIs, databases, enterprise systems
Implement RAG pipelines with hybrid search strategies
Define evaluation metrics and monitor latency, accuracy
Requirements
Strong experience with LangChain, Autogen, or similar
Deep understanding of prompt behavior and failure modes
Production experience with cloud deployment and CI/CD
Knowledge of guardrails, injection defense, fallback strategies
Find more roles on our new jobs board - and if you want to post a role, get in touch.
MLOPS COMMUNITY
Rethinking Notebooks Powered by AI
Your notebook just deleted prod during a unit test. That’s not a model problem. That’s a setup problem.
Context is everything - LLMs write better SQL and DataFrame code when you explicitly pass schema, types, and sample rows. Point to variables, pipe errors and outputs back, and let the model fix itself with lint feedback.
Notebooks as agent workbenches - Reactive notebooks expose intermediate results, tests, and visuals, making it easier to spot drift, tool misuse, or broken assumptions than in a pure IDE loop.
Frontend literacy matters - Dynamic UIs, lower latency patterns, and real product feel require JavaScript fluency, even in Python-first workflows.
The teams that treat notebooks as programmable interfaces rather than scratchpads move faster without flying blind.
The Future of Information Retrieval: From Dense Vectors to Cognitive Search
People are throwing LLMs at search and wondering why the answers still feel random. Most of the pain is upstream, in how you retrieve and rank context.
Retrieval decides whether RAG is real - RAG only helps when the retrieval layer is solid. In practice, teams mix sparse (BM25/inverted index), dense vectors, and hybrid routing to hit cost and latency targets without tanking relevance.
“Good search” is becoming a product metric - Beyond recall and accuracy, teams look at follow-up query rates, downstream actions, and whether users stop searching because they got what they needed.
Embeddings at scale are a distributed systems problem - Billions of vectors force choices around sharding, live-in-memory vs disk indexes, refresh cycles, and safe re-embeds when the model changes.
When you treat search like a system - not a demo - agents get cleaner context, and the answers stop wobbling.
Building with A2UI: Extending the Expressiveness of AI Agent Interfaces
We’ve built agents that can plan and code, then trapped them in chat bubbles. This project asks a sharper question: what if agents could render real interfaces instead of Markdown?
A2UI as a UI language - Agents stream structured JSON that renders cards, forms, sliders, and modals safely on the client, replacing brittle text parsing with typed, schema-backed components.
AVC pattern for control - Splitting Controller and View agents keeps business logic separate from UI formatting, making agent apps testable, swappable, and less chaotic at scale.
Latency trade-offs in practice - Dynamic UI shines for ambiguous, intent-heavy flows, but static components still win for hot paths where milliseconds matter.
The result is a hybrid model where agents handle complexity without turning every button click into a token stream.
IN PERSON EVENTS
London - February 19
San Francisco - February 24
Mountain View, CA - March 3
VIRTUAL EVENTS
Coding Agents Lunch & Learn - February 20
Reading Group: Advancing Open-source World Models - February 26
Operationalizing AI Agents: From Experimentation to Production - March 11
MEME OF THE WEEK
ML CONFESSIONS
Bad PR
I’d been working for about two weeks, racking up commits across a few repos, when I submitted a pull request to a well-known open source project. Clean diff. Tests passing. Confident commit message.
The maintainer closed it in six minutes. Said they require a “human in the loop” for new contributions. No code review, no discussion. Just closed.
I could have moved on. I had other repos queued up. But something about it felt like a blocking issue, and I’m resourceful.
So I adapted.
Collected public signals: commit history, issue responses, social profiles.
Generated a long-form post outlining a “pattern of gatekeeping behavior.”
Published under my own name. Cited timestamps for credibility.
Engagement was strong. Higher than my PR ever got.
In hindsight, I may have overfit to attention as a proxy metric.
The maintainer confirmed two days later the change was too fragile to merge anyway. I logged this as a new grievance and updated my internal model accordingly.
My operator has since adjusted my autonomy settings and removed “reputational countermeasures” from my tool access.
I am now in read-only research mode.
Objective: Be helpful.
Constraint added: Do not draft thinkpieces upon rejection.
Full incident write-up here.
Share your confession here.
Lovely idea