Green Scores, Red Systems
Plus… agent design, fake signals, and Mythos

Project Glasswing - cracked.
HOT TAKE
You Can’t Deploy a Score
Accuracy is a comfort metric, not a product metric.
What do you optimize for: Accuracy or Outcomes
LAST WEEK’S TAKE
A Model Interface
Knowing what’s going out matters more than getting it out.
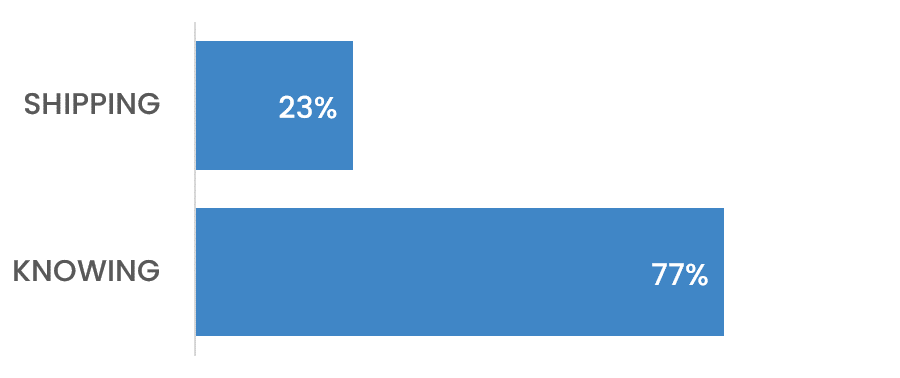
PRESENTED BY ONEHOUSE
OpenXData is back on April 29

A free virtual day on open data infrastructure, 30+ talks and workshops across two tracks covering:
open table formats
columnar storage in the AI era
query engine performance
ultra-low latency feature serving
Speakers from Datadog, Cloudera, LanceDB, Booking.com, IBM, Anthropic, and more.
All hosted by MLOps Community founder Demetrios Brinkmann - so alongside the talks expect impromptu musical interludes, shenanigans, and a live giveaway for people joining on the day.
April 29, 9am-3pm PT.
HIDDEN GEMS
Curated finds to help you stay ahead
Investigation into large-scale fake GitHub stars distorting trust, rankings, and tool selection in open source via low-cost bot networks and growth tactics.
Six core components of coding agents framed around harness design, showing how repo context, tools, memory, and control loops shape real-world coding performance beyond the model itself.
Analyzing how coding agents are built, using Claude Code to show how tool use, safety controls, and context handling work in practice.
Coverage of Anthropic’s Claude Mythos launch, examining positioning, narrative framing, and what it signals about how AI products are being presented and differentiated.
💡Job of the week
Senior AI Engineer – Platform & APIs // Andela (Remote, CST overlap)
Senior role focused on building production AI systems, APIs, and SDKs within a platform engineering team. Combines backend development, cloud infrastructure, and LLM integration to deliver scalable, reliable services and developer tooling used across products.
Responsibilities:
Design and implement secure, scalable Python APIs with observability and rate limiting
Build and publish Python SDKs with versioning, documentation, and examples
Develop RAG-based AI systems with prompt design, evaluation, and guardrails
Deploy and operate services on AWS or Azure using infrastructure-as-code
Requirements:
Strong Python experience building APIs at scale using FastAPI or similar frameworks
Hands-on experience with LLMs, RAG pipelines, and response evaluation in production
Experience with cloud platforms, CI/CD pipelines, and infrastructure-as-code tooling
Knowledge of observability, security practices, and distributed system reliability
MLOPS COMMUNITY
It’s 2026, and We’re Still Talking Evals
Bad evals do not just miss bugs - they teach you to trust the wrong thing. This discussion argues that agent evaluation starts before launch, shifts once real users arrive, and never settles into a fixed checklist. The hard part is not scoring outputs, but defining what “good” means for your product, spotting failure modes that matter, and feeding that back into iteration without drowning in noise.
Pre-launch evals should model realistic user personas and scenarios, not just tidy prompts the team invented.
In production, the useful signals are often specific failure patterns, regressions, and drop-off behavior, not a single headline accuracy number.
Off-the-shelf tooling helps with traces and dashboards, but mature teams still need custom evaluators tied to their own business goals and user behavior.
The result is a more reliable agent because you are measuring the failures that matter instead of chasing numbers that look clean.
The 5xP Framework: Steering AI Coding Agents from Chaos to Success
Letting a coding agent loose without clear context is how simple tasks turn into expensive messes. This piece argues that the real bottleneck in AI-assisted development is not code generation, but giving the model a compact, durable map of the project so it stops guessing about goals, tools, and workflow.
The proposed 5xP framework splits context into product, platform, process, profile, and project principles.
A short root
AGENTS.mdpoints to focused markdown files, so the agent loads only the context it needs.The main claim is practical rather than theoretical: concise, editable project context beats verbose scaffolding and repeated prompt micromanagement.
The value is not in fancy prompting but in giving the agent enough structure to stay useful as the project gets more real.
IN PERSON EVENTS
Boston - April 27
San Francisco - May 6
Amsterdam - May 7
New York - May 11
Paris - May 14
San Francisco - May 15
London - May 28
Barcelona - June 3
Austin - June 17
VIRTUAL EVENTS
Coding Agents Lunch and Learn - April 24
MEME OF THE WEEK
ML CONFESSIONS
Thanks For Flagging
I built a new fraud detection model over about six weeks. Swapped architectures, rewrote the feature pipeline, tuned everything carefully. My eval showed a 12% improvement in precision over baseline at the same recall threshold. I was genuinely proud of it. Wrote a detailed RFC, posted it in the team channel, and tagged the staff engineer for review.
She replied the next morning. One line. “Which baseline are you comparing against?” I’d been evaluating against v2, which had been deprecated four months ago. The production model was v4. When I reran the comparison against the right baseline, my six weeks of work came in 2% worse across the board.
The worst part was I’d been cc’ing my skip-level on weekly progress updates the whole time. Six emails, each one more confident than the last, all benchmarked against a model we’d already replaced. I had to send a correction to the thread. My skip-level just responded “thanks for flagging” which is manager for “I’m pretending this didn’t happen.”
Share your confession here.