Don’t Let ‘Open’ Mean Exposed

Tom Cruise’s Mission: Impossible insurance bill looks cheap next to Silicon Valley’s tab for getting agents into the field.
HOT TAKE
CI Heat Check
Smoke tests beat unit tests for ML pipelines. If you only add one thing to CI, make it this.
Where do you stand on smoke tests, are they on fire, or just blowing smoke?
LAST WEEK'S TAKE
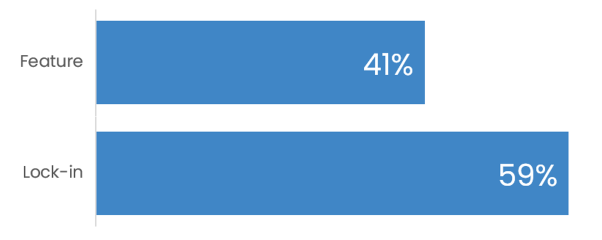
Memory Lock
Last week's votes are in - most think memory leans more trap than treasure.
PRESENTED BY QDRANT
Speed Meets Precision: Introducing MUVERA for Faster Multi-Vector Search

Multi-vector embeddings offer richer, more nuanced representations than single-vector models — but they often come at the cost of speed.
MUVERA, introduced by Google Research, bridges that gap by producing a single-vector proxy for fast initial retrieval, then re-ranking with the full multi-vector representation.
In our article, we walk through how MUVERA embeddings are created (using SimHash, random projections, and clustering), and how they can deliver ~7× speed improvements with nearly identical search quality when paired with reranking. If you're using or considering multi-vector representations, this piece shows how to get the best of both worlds.
Don’t settle for slow searches; apply MUVERA in your systems and unlock both speed and relevance.
HIDDEN GEMS
Curated finds to help you stay ahead
AgentArch enterprise agent benchmark evaluates 18 agent architectures in real enterprise tasks, probing orchestration, memory, tools, and prompt styles.
Nondeterminism in LLM inference and how to design pipelines that stay reproducible and consistent, even as workloads scale.
Bypassing LLM safety with HaPLa uncovers a high-success black-box jailbreak method, highlighting weaknesses in current guardrails.
Nano Banana vs GPT-4O comparison looks at how a newer model stacks up against GPT-4O, in terms of capabilities, trade-offs, and what each is better suited for.
Job of the week
Senior AI Product Engineer, Fullstack // Arize (Remote)
This role is on the Fullstack team, building infrastructure and interfaces that support AI observability workflows. You’ll work across frontend and backend systems to deliver scalable features and intuitive tools used by engineering teams working with ML and LLMs.
Responsibilities
Build and maintain scalable fullstack applications in React and TypeScript
Design and implement APIs supporting ML and LLM workflows
Develop reusable React components for interactive product features
Collaborate with product and design on architecture and user experience
Requirements
5+ years frontend experience with React and TypeScript
Strong background building complex SaaS platforms at scale
Ability to debug distributed systems in collaborative environments
Interest in AI, LLMs, and emerging ML technologies
Find more roles on our new jobs board - and if you want to post a role, get in touch.
MLOPS COMMUNITY
Trust at Scale: Security and Governance for Open Source Models
Pulling the wrong “open” model can open a shell and leak your org’s keys. Enterprises are countering that risk with boring but effective plumbing.
Central LLM gateway: one entry point to route requests, block disallowed hosts, swap models, and apply policy and cost controls.
Curated model catalog: scan and whitelist a small set, enforce licenses, record provenance and metadata for audits.
Org-wide visibility: detect where SDKs are used across code, including on prem and multi-cloud, to prepare for compliance.
Lock down the doorway first, and that “one click” exploit never gets in.
Smoke Testing for ML Pipelines
A single missing column can crash an ML pipeline. With smoke tests, you catch it in seconds instead of discovering it after an eight-hour training run.
End-to-end checks: Run pipelines with synthetic datasets to catch schema mismatches, broken preprocessing, or missing dependencies before wasting compute.
Random vs. controlled data: Use randomized values for schema validation, or embed simple patterns to confirm models still detect expected signals.
Beyond data: Extend smoke tests to model registries, verifying training, storage, and reload paths.
A few quick tests give you confidence that the whole pipeline is solid, so you can focus on the model instead of firefighting.
IN PERSON EVENTS
London - September 18
Austin - September 18
Seattle - September 25
Denver - September 25
Miami - September 25
MEME OF THE WEEK

ML CONFESSIONS
Brewed Suspicion
In my first few months at the startup, we had a big push to improve the fraud detection system before a launch. I was green and wanted to prove myself, so I cranked out this “clever” feature that used merchant descriptions. I didn’t think too hard about cleaning them up - just shoved the raw text in.
Two weeks later, alarms started firing non-stop. Turned out my feature was flagging almost every transaction from a certain coffee chain as suspicious because their receipts sometimes included emoji in the merchant text. The model treated it like an out-of-vocabulary token storm and threw up red flags everywhere.
We had to hard-exclude the chain until I fixed it. For about a week, people joked that I’d invented an “anti-coffee” bias.
Share your confession here.